Узнайте, как правильно использовать данные в вашей цепочке поставок
20 октября 2021 г.

20 октября 2021 г.
Современная модель потребления основана на цифровой модели, генерирующей все больше и больше данных, которые необходимо обрабатывать. Эти данные - настоящая золотая жила для компаний: они преобразуют модели бизнеса и цепочек поставок из транзакционных, когда сделка совершалась только в момент спроса, в предиктивные модели, позволяющие лучше диагностировать аномалии благодаря обмену информацией.
В нашем обществе потребления клиенты изменчивы как никогда, поэтому важно и необходимо использовать имеющиеся в вашем распоряжении данные. Конкуренция становится все сильнее, а ваши клиенты - все требовательнее. Поэтому вы должны владеть своими данными, чтобы иметь возможность анализировать, как вы реагируете на запросы ваших клиентов в условиях конкуренции.
При использовании данных вы должны руководствоваться тремя основными целями:
Благодаря использованию и анализу данных вы сможете обеспечить непрерывную диагностику и полный контроль важных показателей вашей деятельности S&OP (Sales &Operation Planning). Вы сможете лучше координировать решения о закупках и продажах в соответствии с внутренними возможностями вашей компании.
Анализируя данные вашей цепочки поставок, вы сможете оперативно получать уведомления о проблемах, мешающих ее оптимальной работе, чтобы как можно быстрее решить их и тем самым ограничить последствия сбоев.
Когда вы освоите анализ данных, у вас будет достаточно исторических данных, чтобы с точностью и уверенностью предсказать будущее движение запасов (товары с высокой сезонностью и т. д.) и, таким образом, повысить точность и эффективность управления вашей цепочкой поставок.
Прежде чем вы сможете оптимально использовать свои данные, необходимо подготовить их и рабочую среду, чтобы все анализы можно было проводить с использованием надежных и безопасных данных.
Каждый отдел вашей компании располагает различными данными, которые могут быть полезны для анализа. Поэтому вам следует начать со сбора данных от различных сотрудников. После того как эти данные будут собраны, вам придется их стандартизировать: ведь в каждом отделе нет одинаковых процессов обработки данных. Вам придется создать и распространить среди сотрудников процессы стандартизации, чтобы данные, которые вы соберете позже, уже были в правильном формате, что сэкономит ваше время.
Определив, какие данные необходимо собрать, вы быстро поймете, какой объем данных нужно хранить. Затем вам нужно будет выбрать способ хранения данных в структурах, достаточно мощных, чтобы вместить все ваши данные, но при этом способных часто обновлять различные базы данных. Например, вы можете рассмотреть возможность хранения данных в нескольких местах, чтобы избежать проблем в случае технической или природной катастрофы, которая уничтожит оборудование для хранения.
Наличие серверов хранения большой емкости не будет единственным критерием при выборе способа хранения. Главным критерием должна быть безопасность ваших данных. Вам действительно придется работать с конфиденциальными данными о вашей компании и ваших клиентах (контактными данными или даже платежной информацией), которые должны быть полностью защищены, чтобы к ним не могли получить доступ другие люди. Для оптимальной защиты можно использовать удаленные серверы, доступные в облаке. Отказавшись от хранения данных внутри компании, вы также избавитесь от необходимости управлять операциями по обслуживанию серверов и рисками нестабильности, обратившись к профессионалам. Они продублируют данные на нескольких серверах, чтобы снизить естественные и технологические риски и обеспечить непрерывность обработки данных.
После того как вы собрали все данные, подлежащие обработке, выбрали способ хранения и обеспечили их сохранность, необходимо провести оценку качества данных. Действительно, качественные данные - это данные, которые соответствуют реальности, уникальны, понятны, структурированы и документированы. Вам придется постоянно проводить эту оценку, чтобы применять ее к новым данным, собранным впоследствии вручную или автоматически.
Среди всех имеющихся в вашем распоряжении данных вам придется научиться выбирать наиболее актуальную информацию, чтобы оптимизировать анализ и прогнозы и быстрее и легче адаптировать свою цепочку поставок.
В первую очередь необходимо собрать данные, касающиеся всей вашей цепочки поставок. Вы должны использовать данные, обеспечивающие типичные показатели, для создания качественной истории данных, что является критерием ускорения окупаемости инвестиций. Для создания базы данных по цепочке поставок вам необходимо выбрать следующую информацию:
o Хранилище товаров: бренды, цены, срок службы, объем и т. д,
o Репозиторий поставщиков: имена, условия закупок, каталоги, частота заказов и т. д,
o Хранилище клиентов: контактная информация, история покупок и т. д,
o Информация о вашей логистической сети: склады, хабы, магазины и т. д,
o Информация о ваших складских операциях: продажи, заказы, поступления, инвентаризация и т.д.
Эта информация будет адаптирована в соответствии с типологией вашей компании: в зависимости от сектора вашей деятельности она может быть разной (например, вам придется собирать данные с мобильных пунктов обслуживания, если они у вас есть).
Еще до внедрения системы управления данными в вашем распоряжении уже имеется большое количество данных. Эти данные, распределенные между различными отделами, очень ценны: они помогут вам создать историю данных, которая укрепит вашу способность прогнозировать различные риски, связанные с вашей цепочкой поставок. Лучший способ собрать и обработать эти данные - назначить менеджера проекта по управлению данными, который будет отвечать за картирование, сбор и предоставление всех данных, которые ваша компания могла генерировать в прошлом.
Помимо обработки внутренних данных вашей компании, вам также потребуется интегрировать экзогенные данные, то есть данные, которые генерируются не в вашей компании, а в вашем окружении. Они помогут вам сделать ваш анализ более актуальным. В зависимости от сферы вашей деятельности вы можете захотеть объединить различные типы экономических и демографических данных, которые влияют на ваш бизнес.
После создания базы данных вам нужно будет постоянно поддерживать ее в актуальном состоянии.
Для начала вам нужно полностью проанализировать свою базу данных, чтобы исключить две наиболее распространенные ошибки в данных:
o Нереалистичные данные: Нереалистичные данные - это данные, которые не могут точно отражать реальность. В контексте управления запасами нереалистичные данные могут, например, соответствовать отрицательным запасам или количеству продаж, значительно превышающему уровень запасов.
o Неструктурированные данные: Неструктурированные данные - это данные, которые неправильно связаны с остальными данными. Например, это может быть продукт, который неправильно связан с его поставщиком. Неструктурированные данные могут вызывать проблемы не только при анализе данных, но и при автоматизации процессов (в данном случае пополнения запасов продукции).
После того как вы определили, какие ошибки закрались в ваши данные, вам необходимо очистить базу данных, чтобы устранить их и получить достоверные, реальные и подробные данные. Вам нужно будет предотвратить повторение этих ошибок: важно определить их источник: возникают ли они в процессе обмена данными, их обработки или сбора? В большинстве случаев они возникают из-за человеческой ошибки: поэтому необходимо установить новые точные и подробные процессы обработки данных и передать их всем вашим сотрудникам.
После того как все данные собраны и подготовлены к обработке, можно переходить к этапу анализа, чтобы провести диагностику цепи поставок.
KPI (Key Performance Indicator) - это критерий для анализа общей эффективности системы. Важно установить KPI, чтобы проводить диагностику в соответствии с точными критериями. Этих критериев может быть несколько, и они должны быть адаптированы к различным этапам вашей цепи поставок: скорость оборота запасов, скорость обслуживания, процент удовлетворенности, время выполнения заказа и т. д. Именно отслеживание динамики KPI позволит вам предупредить о сбоях в цепи поставок.
Для оптимальной диагностики вам придется обратиться к эксперту по цепочкам поставок: он знает всю вашу цепочку поставок с внутренней точки зрения. Он сможет использовать мощный инструмент, который представляют собой данные, для анализа и более легкого поиска истоков различных проблем, которые могут нарушить вашу цепочку поставок.
Увеличение количества источников сбора данных и развитие технологий IoT (Интернета вещей) в ближайшие годы приведет к появлению все большего количества данных. Эти данные, все более и более актуальные, будут необходимы для постоянного совершенствования цепочки поставок, и особенно для внедрения новых технологий, таких как искусственный интеллект.
Таким образом, использование данных станет важным критерием для обеспечения эффективности вашей цепочки поставок, выявления аномалий и прогнозирования действий, чтобы всегда лучше удовлетворять запросы ваших клиентов.
Learn how to properly use the data in your supply chain
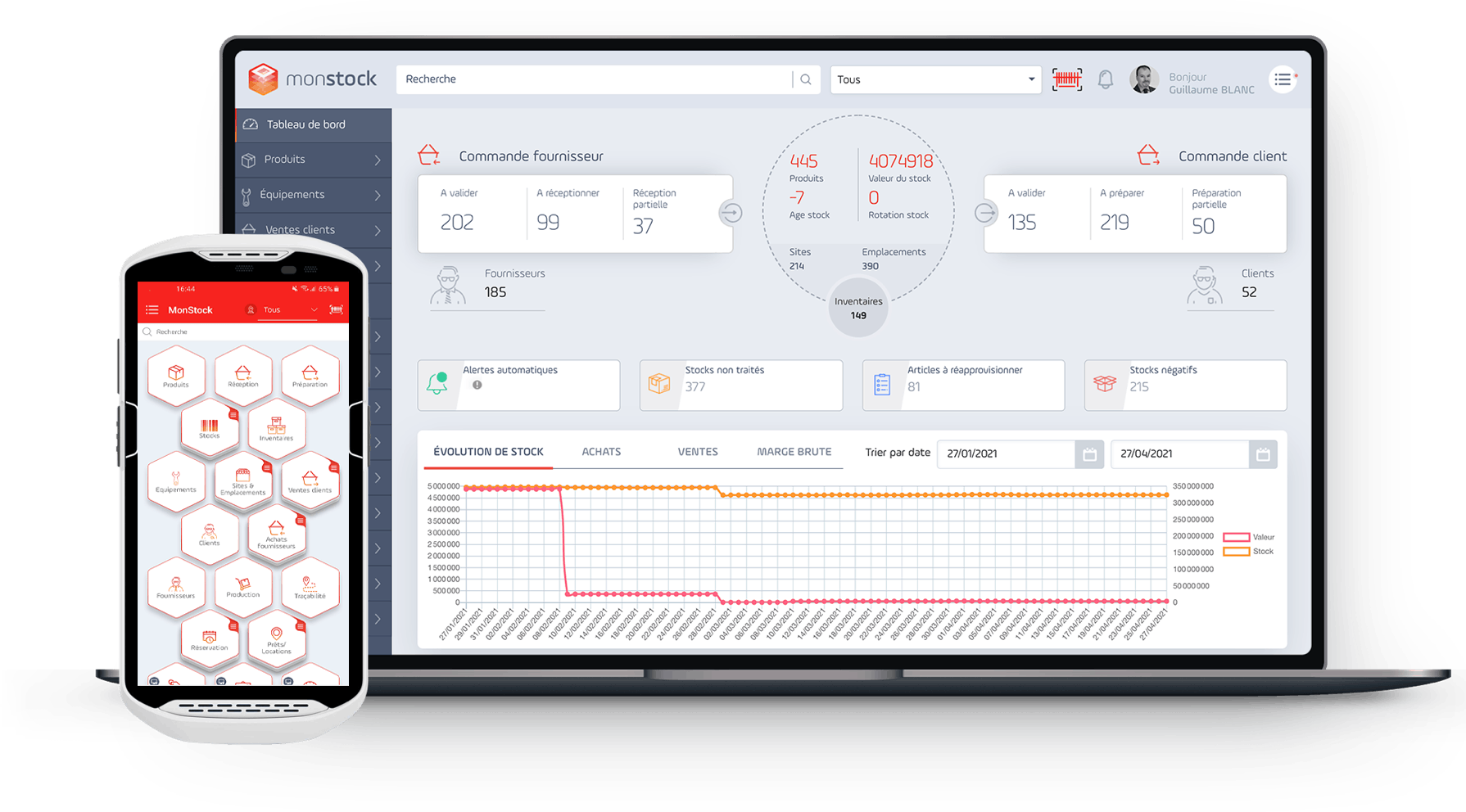
Получите лучшие показатели управления вашей компанией благодаря предложению по визуализации данных и отчетам, которые предоставляет в ваше распоряжение компания Monstock. Мы поможем вам составить отчеты, чтобы оптимизировать цепочку поставок.
Узнайте, как вы можете использовать Monstock для управления данными с помощью Control Tower и других инструментов бизнес-аналитики.
Для получения дополнительной информации: контакт с командой Monstock.

28 сент. 2021 г.